
Некоторое время назад помогал коллегам с подготовкой отраслевых комментариев для СМИ. Так как, в конечные материалы вошла только часть моих тезисов, решил сгруппировать и выложить их в заметку. Заголовки соответствуют вопросам журналистов.

Как и где формируются потоки Big Data
Датифицировать и формировать большие данные для анализа можно практически из всего. Примеры:
- Внутреннее состояние устройств и компонентов:
- внутренние режимы
- коды (в случае локомотива)
- сохраненную в памяти информацию и метаданные
- Внешнее состояние, собираемое через датчики:
- температуру
- вибропараметры и данные с гироскопов
- фото и видео
- аудио
- Местоположение
- Информацию о действиях и взаимодействиях систем:
- системные логи
- время между действиями одной системы
- время ответа систем
- внутренние запросы
- Производные данные:
- результаты виртуального тестирования
- агрегированные метрики
О любом сложном механизме, в принципе, можно собрать бесконечное количество данных. Помимо расширения набора метрик, можно увеличивать точность и частоту сбора.
Сегодня самой “генерирующей данные” отраслью является авиационная, но остальные тоже подтягиваются. Современные самолеты имеют на борту тысячи датчиков и генерируют свыше 10 ГБ (гигабайт) данных в секунду и сотни терабайт данных за полет.
Способность датифицировать предметную область зависит от:
- Датчиков (внешние, внутренние), способных выдавать данные, которые можно сохранять, сопоставлять и обрабатывать
- Каналов передачи данных, способных передать объем собираемой информации, алгоритмов и методик сжатия данных
- Способности эти данные сохранить
Генерировать “данные ради данных” – контрпродуктивно, как минимум, в ближайшей перспективе, пока мы научились автоматически эффективно находить логические связи (Unsupervised Learning - это не то)
Чтобы успешно использовать Big Data нужны:
- Возможность связать данные между собой (идентификаторы устройств/пользователей, временные метки и т.д.)
- Хотя бы минимальная значимость данных для тех целевых параметров, которые пытаемся оптимизировать
- Умение выработать управляющее воздействие
В традиционных (старых) управленческих системах является «нормой», когда 95+% собираемых данных в силу разных причин не используется для какого-либо принятия решения, и собирается, “чтобы было”.

Для чего в промышленности используются большие данные
Большие данные в промышленности уже используются для ряда задач:
- Своевременное выявление и устранение потерь в производственных процессах
- Повышение стабильности технологических процессов
- Оптимизация расхода энергии
- Оптимизация сетевого планирования
- Оптимизация ТОиР
- Прогнозирование отказов оборудования (Предиктивная аналитика)
В качестве примера можно привести реализуемые проекты в железнодорожной отрасли РФ:
- Цифровизация производства и создание цифровых двойников заводов транспортного машиностроения
- Цифровизация сети сервисно-локомотивных депо
- Предиктивная аналитика состояния узлов и агрегатов локомотивов
- Автоведение локомотивов
Если не ограничиваться РФ, то можно почитать исследование ВЭФ/McKinsey с большим количеством кейсов.
Кто является получателем и распорядителем Big Data, вопросы ответственности и принятия решений
Даже сырые данные небезосновательно рассматриваются многими компаниями как актив, способный приносить ценность, даже если компании сейчас не могут ими воспользоваться (сделать предиктивные модели или real-time системы реагирования).
В авиации уже существует бизнес-модель, когда авиапроизводители, которые собирают технические данные с произведенных ими самолетов, могут выступать техническими экспертами и арбитрами в сделках на вторичном рынке.
Ответственность за применение - пока, по умолчанию, за конечными операторами систем.
Как можно оценить отношение российской промышленности к использованию больших данных, что препятствует распространению этой технологии, какова здесь политика государства
Судя по общему настроению на рынке, капитализировать тему больших данных хотят все. Пока, в основном, положительное движение в этом направлении - удел крупных промышленных групп и предприятий. Почти каждый крупный промышленный холдинг уже запустил или запускает свои программы цифровизации.
Возможности:
- Очень большой потенциал роста эффективности предприятий в РФ
- Много локальных игроков, которые готовы разрабатывать решения в области Big Data и AI
Сложности:
- Нужна высокая культура производства и бизнеса(Цифровая культура)
- Существующий парк оборудования в среденм не поддерживает цифровизацию
- Непростой выбор в части хранения и обработки данных: делать свою инфраструктуру (нужны инвестиции) или довериться облакам (вопросы безопасности)
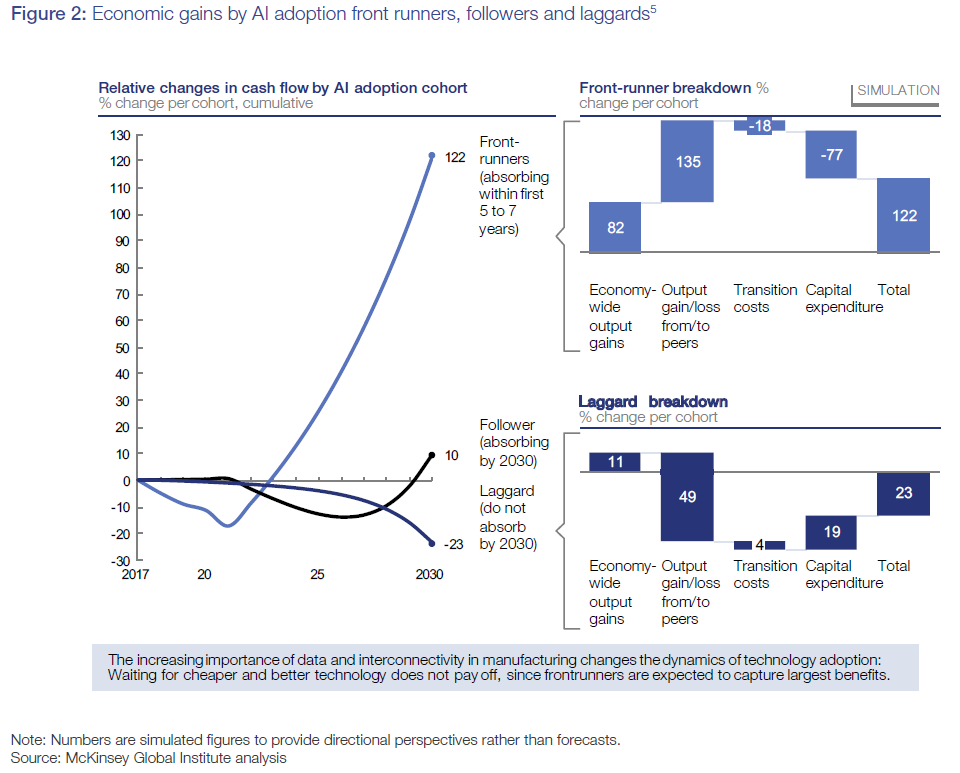
Насколько быстро, по вашему опыту, окупаются такого рода проекты
Есть как быстрые проекты (окупаемость за месяцы), так и медленные (за годы).
Базовая рекомендация для предприятий без опыта инноваций и цифры - начинать с малых проектов. Тем не менее, технологии уже зарекомендовали себя и промышленность готова инвестировать в долгую.
Насколько в применении этой технологии Россия зависима от импортного оборудования и ПО
В части компьютерного железа высокая зависимость. Для работы с Big Data нужно общепромышленное высокопроизводительно оборудование. Отечественные Эльбрусы и Байкалы не годятся, так как слишком дороги в пересчете на мощности.
Платформенное ПО обычно тоже иностранное. Разработка отечественных систем актуальна, и многие компании занимаются созданием своих платформ.
В части прикладного ПО зависимость низкая, так как общеотраслевых универсальных решений нет. Идет формирование рынка и разработка, в том числе отечественных, продуктов.
Еще есть ограничение, связанное с тем, что чтобы собирать Big Data, нужны датчики на оборудовании, и, если оборудование (станки, машины) иностранное, то дооснастить такое оборудование существенно сложнее и зачастую невозможно без участия оригинального производителя.
Как администрирование данных регулируется в правовом поле, какие возможны проблемы на имеющейся регулятивной базе
Для промышленной Big Data отдельного регулирования нет. Есть законы, регулирующие телеком и связь как передачу данных, законы регулирующие компьютерные программы (авторское право) и базы данных.
Данные в общем виде считаются собственностью того, кто их создает, и того, кому «генератор» их передает/лицензирует для использования.
Отдельный блок – персональные, медицинские и другие специализированные виды данных, в случае с которыми существует свое законодательство.

Какие есть преимущества и риски в обмене данными IoT, проблемы безопасности
Преимущества:
- Генерация данных на самих устройствах (рост точности и оперативности)
- Снижение требований к трафику при проведении расчетов/анализе на конечных устройствах
- Автономность систем (M2M общение)
- Оперативность принятия решений и совершения управляющих воздействий
Риски:
- Безопасность
- Утечка данных
- Подделка данных
- Внешнее воздействие на устройства
- В IoT нужно искать баланс между сложностью систем, функционалом и автономностью (энергоэффективность, децентрализация)
Какие возможности для технологических прорывов дает Big Data
- Автономность (5-го уровня, «безлюдность») – у всех на слуху
- Полное исключение «человеческого фактора»: снижение ошибок и выход за границы возможностей человека
- Самокомплектация, самообслуживание по состоянию и самовосстановление
- Сокращение затрат (время, прямые затраты) на разработку, тестирование гипотез и т.д.:
- Автоматизированная разработка и проектирование с AI
- Виртуальные испытания
- Цифровые двойники всего
- Автоматическое нахождение новых логических взаимосвязей между разными факторами и выработка решений